强化学习 人工智能发展的未来引擎
在人工智能的广阔版图中,强化学习正以其独特的“从交互中学习”的范式,从众多技术路径中脱颖而出,成为驱动AI迈向更高智能水平的关键引擎。它不仅是一种算法框架,更代表了一种让机器通过试错、探索与奖励机制来学习和决策的通用方法论,正深刻改变着人工智能基础软件开发的格局。
强化学习的核心范式:智能体的“试炼场”
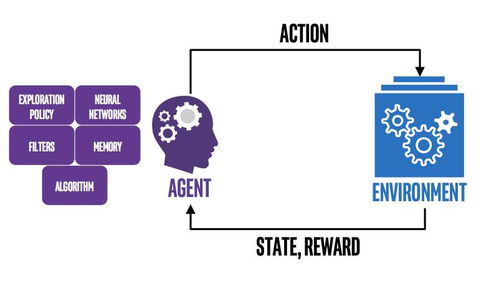
与依赖海量标注数据的监督学习不同,强化学习的核心在于一个智能体(Agent)在环境(Environment)中不断尝试。它通过执行动作(Action)来与环境交互,环境则返回新的状态(State)和相应的奖励(Reward)。智能体的终极目标,就是学习一套最优策略(Policy),以最大化其在整个交互过程中所获得的累积奖励。这个过程宛如一个婴儿通过触摸、摔跤、观察来认知世界,或一个棋手通过无数对弈来精进棋艺。从AlphaGo在围棋棋盘上的“自我博弈”中战胜人类冠军,到智能体在复杂视频游戏中超越人类玩家,再到机器人学习行走、抓取等复杂技能,强化学习已反复证明了其在解决序列决策问题上的强大潜力。
AI基础软件开发的范式革新
强化学习的崛起,正在驱动人工智能基础软件开发发生深刻变革。这主要体现在以下几个方面:
- 从“数据驱动”到“交互驱动”的设计理念:传统AI软件开发高度依赖精心准备的数据集。而强化学习框架要求开发者将问题建模为一个动态的交互环境,设计合理的状态空间、动作空间和奖励函数。这促使软件开发从静态的数据处理,转向构建能够模拟真实世界动态性的仿真平台(如OpenAI Gym、Unity ML-Agents),使得AI可以在安全、高效、可扩展的虚拟空间中先行训练。
- 算法库与框架的专门化演进:为了支持强化学习复杂的训练流程(包括采样、学习、评估等),出现了众多成熟的专用框架和库。例如,DeepMind的Acme、OpenAI的Baselines、伯克利的RLlib(集成在Ray中)以及PyTorch和TensorFlow生态系统下的诸多强化学习工具包。这些基础软件大大降低了研发门槛,让开发者能够更专注于算法创新和问题建模。
- 仿真与真实世界桥梁的构建:一个核心挑战是将在仿真环境中训练的策略迁移到物理世界(“sim-to-real”)。这催生了对物理引擎(如NVIDIA Isaac Sim、PyBullet)、域随机化技术以及自适应控制软件的需求。基础软件不再仅仅是算法实现,更成为连接虚拟训练与实体应用的“数字孪生”平台。
- 系统工程的复杂性提升:强化学习训练通常计算密集、耗时漫长,且需要稳定的分布式系统支持。因此,对高性能计算(HPC)、云计算资源管理、实验跟踪与管理(如Weights & Biases, MLflow)等基础软件设施提出了更高要求,推动了AI开发工具链的全面升级。
未来引擎:驱动通用人工智能(AGI)的探索
强化学习被视为通往通用人工智能(AGI)最有希望的路径之一。其核心优势在于能够处理开放环境中的长期规划问题,并具备自我改进的能力。未来的发展趋势可能聚焦于:
- 样本效率的提升:如何让智能体像人类一样,从少量交互中快速学习,是突破当前瓶颈的关键。元学习、模仿学习与强化学习的结合是重要方向。
- 安全与可解释性:确保强化学习智能体的行为安全、可靠且符合人类价值观,需要开发新的算法和验证软件。
- 多智能体协作:现实世界充满协作与竞争。多智能体强化学习将研究多个智能体在共享环境中的互动,为社会经济系统建模、自动驾驶协同等提供基础,这需要更复杂的环境模拟和通信协议软件支持。
- 与基础模型的融合:将强化学习与大型语言模型(LLMs)等基础模型结合,可以让AI不仅掌握技能,还能理解高层次指令、进行常识推理,从而处理更复杂的现实任务。
走进人工智能的深处,强化学习正以其探索与试错的智慧,为AI系统装上了一台面向未知、寻求最优解的强大引擎。它不仅在围棋、游戏等领域大放异彩,更在机器人控制、资源管理、金融交易、医疗决策等广阔场景中展现出变革性潜力。相应地,人工智能基础软件开发也正围绕强化学习的特性,从环境模拟、算法框架到系统工程,构建起一整套支持智能体“成长”的新基础设施。可以预见,随着算法、算力和基础软件的持续进步,强化学习这台“未来引擎”将持续轰鸣,驱动人工智能向着更自主、更通用、更强大的方向不断前行。
如若转载,请注明出处:http://www.jzycyp.com/product/18.html
更新时间:2026-06-18 03:40:02